
I’ve ran a new set of benchmarks for the CPU and GPU routines, both on Windows 10 and Ubuntu 20.04. I’ve now fixed the performance issue on Linux for CPU computations at small problem sizes, which was caused by an OpenMP behaviour I was not aware of. Whenever OpenMP is used, created thread teams remain in a busy state even after a fork-join is completed, until the execution thread goes out of scope. This means if your program has 2 or more execution threads which use OpenMP, if one of them becomes idle all other execution threads will suffer a performance penalty, particularly pronounced at small problem sizes with quick fork-join sections! This is because their OpenMP thread teams must compete for CPU access with the OpenMP thread team in the idle execution thread. I understand this behaviour reduces overhead associated with OpenMP thread team creation, but I’m really surprised OpenMP doesn’t allow for more resource management control (only available in the very latest OpenMP 5.1 now!) – in my opinion this is a rather poor oversight in the OpenMP specification.
The reason this only affects code compiled on Linux, with libgomp implementation OpenMP resources are thread private, whilst with the Windows implementation they are global.
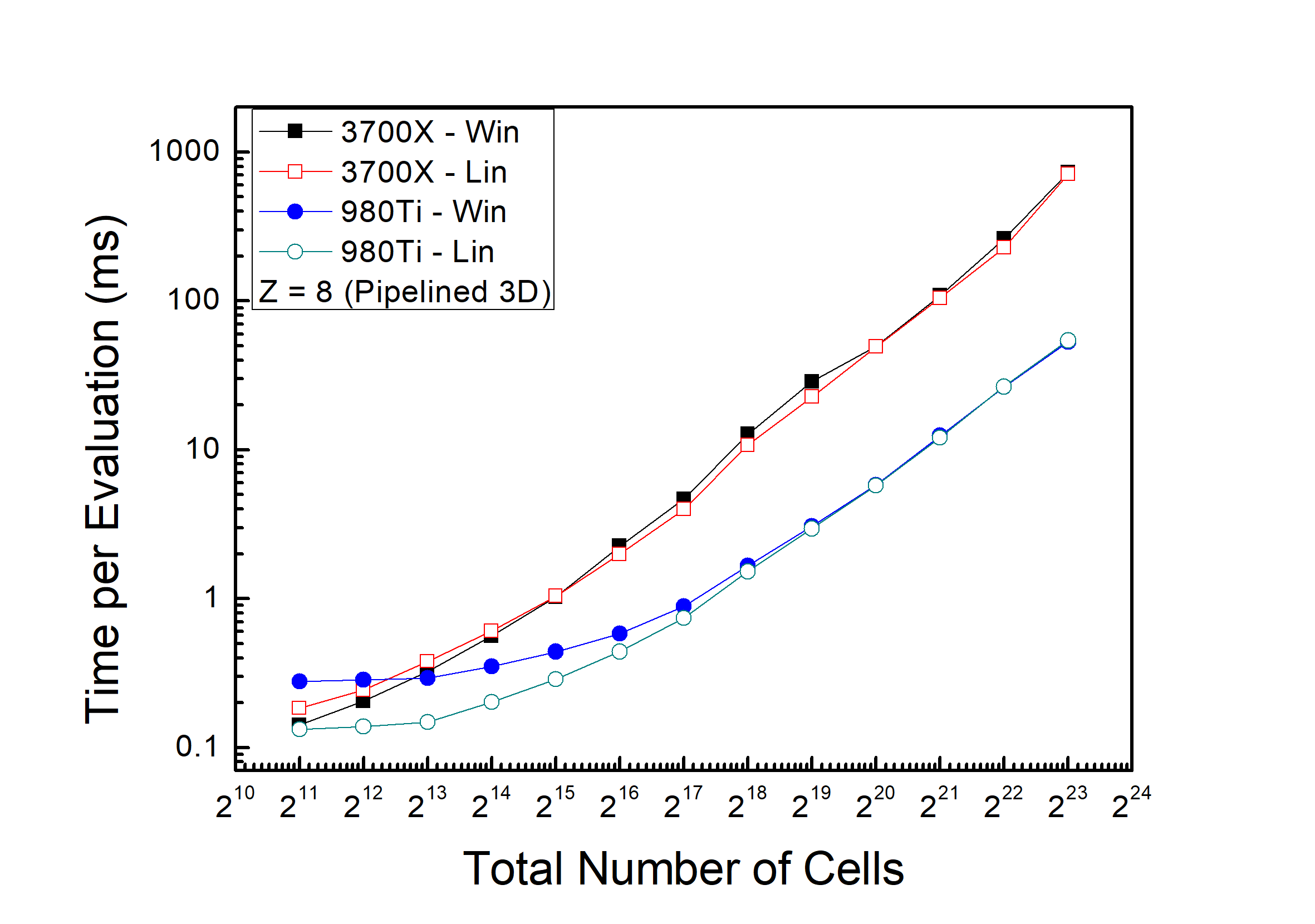
Anyway, problem solved now, and here are the latest benchmarks using the benchmarking script available on GitHub. Figures below should be self explanatory: CPU performance is more or less the same on Windows and Linux. GPU performance is better for small problem sizes on Linux, which I’ve yet to understand.


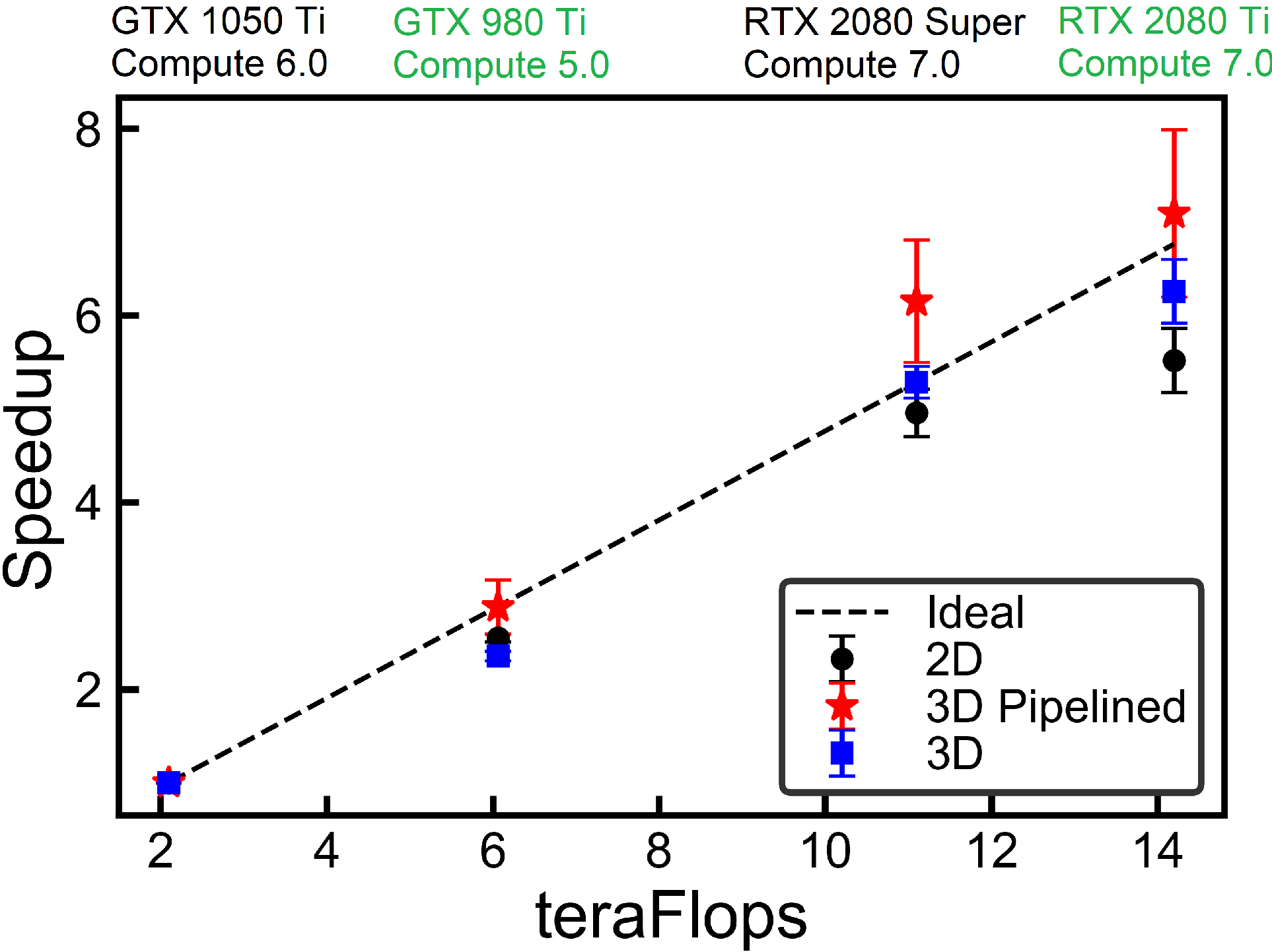
Finally this is the scaling performance for GPU computations (I can’t wait to benchmark the latest RTX 30 series – very hard to get at the moment!).
![]()